Лабы
Reinforcement learning
Обучение с подкреплением
есть набор размеченных данных;есть набор данных, среди которых можно найти структуру;- есть работающая модель, которой можно передать данные на вход и получить значения на выходе.
В общем случае работает так:

Окружение (environment E) – это среда или объект, на который воздействует Агент (например игра).
Агент (agent A) – алгоритм ОП.
Действие (action a) – все возможные команды, которые агент может передать в Окружение (среду).
Состояние (state s) – текущее состояние возвращаемое Окружением.
Награда (reward r) – мгновенная награда, возвращаемая Окружением, как оценка последнего Действия.
Политика (policy P) – Стратегия, которую использует Агент, для определения следующего Действия на основе текущего Состояния среды.
Value (V(s)) или Estimate (E) – ожидаемая итоговая Награда Стратегии в текущем Состоянии. (Встречается в литературе два варианта Value – значение, Estimate – оценка.)
Q-value (quality Q(s,a)) – оценка Качества Стратегии для Состояния и Действия.
Классификации моделей:


Марковский процесс принятия решений
Есть цепь Маркова, в которой события – Состояния Окружения, а переходы определяются Действиями Агента в соответствии с некоторой Стратегией (подробнее). За каждый переход дается Награда, и наша цель – максимизировать ее.
Большинство алгоритмов марковских процессов принятия решений основаны на итерации уравнения Беллмана с фиксированной точкой.
Q-learning
Если описанный выше граф представить в виде матрицы связности, где в каждой ячейке будет отмечена Награда за переход в соседнюю ячейку (это и есть Q-value), получим что-то такое:
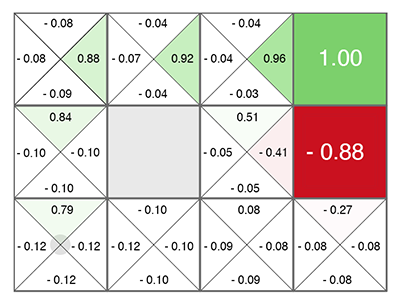
Остается только двигаться в ту сторону, где больше зеленого цвета.
DQN
Если заменить рассчет чисел в ячейках таблицы выше с уравнения Беллмана на нейронную сеть, а точнее обучая нейронную сеть по этой формуле, то получится DQN.
Действия могут быть только дискретными значениями.
Policy Gradient
Исполняем Действия, предсказанные нейросетью, и смотрим, какую Награду набрали за эпизод. Динамику изменения Награды используем для расчета градиента и последующего обратного распространения ошибки.
Actor-critic, DDPG
Есть две сети — одна предсказывает какие Действия надо совершить (Actor – Актер), а вторая оценивает насколько эти Действия хороши (Critic – Критик). Число $Q(s,a)$, выданное второй сетью, точно также можно использовать для вычисления градиента, которым обновлять веса первой сети, как мы делали выше с Наградой. Ну, а вторая сеть обновляется обычным путем, согласно реальному прохождению эпизода.
DDPG является прямым continuous (непрерывные действия) конкурентом DQN с его дискретными действиями.
Довольно подробно разобранный пример на Python.
Advantage Actor Critic (A3C/A2C)
Для расчета градиентов будем использовать не число $Q(s,a)$, а так называемое Преимущество (Advantage): $A(s,a) = Q(s,a) – V(s)$. Число $A(s,a)$ показывает не абсолютное Качество $Q(s,a)$ выбранных действий, а относительное Преимущество – насколько после предпринятых действий станет лучше, чем текущая ситуация $V(s)$. Если $A(s,a) > 0$, то градиент будет изменять веса нейросети, поощряя предсказанные сетью действия. Если $A(s,a) < 0$, то градиент будет изменять веса так, что предсказанные действия будут подавляться, т.к. они оказались плохие.
В таком случае, достаточно предсказывать только $V(s)$ (а награду мы посмотрим уже по факту что получится в реальности), и две сети – actor и critic, можно объединить в одну, которая получает на вход Состояние, а на выходе разделяется на две головы head: одна предсказывает Действия, а другая предсказывает $V(s)$. Такое объединение помогает лучше переиcпользовать веса, т.к. обе сети должны на входе получать Состояние. Впрочем, можно использовать и две отдельные сети.
Asynchronous Advantage Actor Critic (A3C) имеет сервер, собирающий результаты от множества Актеров и обновляющий веса как только набирается батч batch нужного размера.
Потом появился Advantage Actor Critic (A2C) – синхронная версия A3C, в которой сервер дожидается окончания эпизодов у всех Актеров и только после этого обновляет веса.
TRPO, PPO, SAC
В A3C/A2C бывают резкие изменения, которые портят предыдущий опыт. В результате добавления ограничения изменения нейронной сети при каждом обновлении, чтобы веса резко не менялись, получились TRPO (Trust Region Policy Optimization) и PPO (Proximal Policy Optimization).
В SAC (Soft-Actor-Critic) добавлена цель при обучении – повышать энтропию в Стратегии, чтобы агент был способен действовать в более случайных ситуациях.
Итого, общая рекомендация в современном Reinforcement Learning: использовать SAC, PPO, DDPG, DQN (в таком порядке, по убыванию)*.
Model-Based
Если нейросеть может прогнозировать реальный мир (это и есть model-based подход, в общем смысле), то можно проводить обучение целиком в воображении, так сказать. Эта концепция в Reinforcement Learning получила название Dream Worlds, или World Models.
Imitation Learning
Так, OpenAI получилось пройти игру Montezuma’s Revenge. Фокус оказался прост – помещать агента сразу в конец игры (в конец показанной человеком траектории). Там с помощью PPO, благодаря близости финальной награды, агент быстро учится идти вдоль траектории. После этого помещаем его немного назад, где он быстро учится доходить до того места, которое он уже изучил. И так постепенно сдвигая точку “респавна” вдоль траектории до самого начала игры, агент учится проходить/имитировать траекторию эксперта в течении всей игры.
Curiosity (любопытство)
Очень важным понятием в Reinforcement Learning является любопытство (Curiosity). В природе оно является двигателем для исследования окружающей среды.
Проблема в том, что в качестве оценки любопытства нельзя использовать простую ошибку предсказания сети, что будет дальше. Иначе такая сеть зависнет перед первым же деревом с качающейся листвой. Или перед телевизором со случайным переключением каналов. Так как результат из-за сложности будет невозможно предсказать и ошибка всегда будет большой. Впрочем, именно это и является причиной, почему мы (люди) так любим смотреть на листву, воду и огонь. И на то, как другие люди работают =). Но у нас есть защитные механизмы, чтобы не зависнуть навечно.
Где взять готовые модели, чтобы не пилить их ручками
Keras-RL
pip install keras-rl2
Доступные Агенты*:
| Название | Реализация | Наблюдаемое пространство | Пространство действий |
|---|---|---|---|
| DQN | rl.agents.DQNAgent | дискретное или непрерывное | дискретное |
| DDPG | rl.agents.DDPGAgent | дискретное или непрерывное | непрерывное |
| NAF | rl.agents.NAFAgent | дискретное или непрерывное | непрерывное |
| CEM | rl.agents.CEMAgent | дискретное или непрерывное | дискретное |
| SARSA | rl.agents.SARSAAgent | дискретное или непрерывное | дискретное |
SpinUp от OpenAI
Не для Windows, но там можно попробовать через WSL.
Есть реализация следующих алгоритмов*:
- Vanilla Policy Gradient (VPG)
- Trust Region Policy Optimization (TRPO)
- Proximal Policy Optimization (PPO)
- Deep Deterministic Policy Gradient (DDPG)
- Twin Delayed DDPG (TD3)
- Soft Actor-Critic (SAC)
Для каждого алгоритма есть две реализации (PyTorch и TensorFlow).
pyqlearning
https://pypi.org/project/pyqlearning/
Tensorforce
https://tensorforce.readthedocs.io/en/latest/
MMLF
https://mmlf.sourceforge.net/learn_more/agents_and_environments.html#existing-agents
RlPy
https://rlpy.readthedocs.io/en/latest/
- Q_Learning
- SARSA
- Greedy_GQ
- LSPI
- LSPI_SARSA
- NaturalActorCritic
Задание
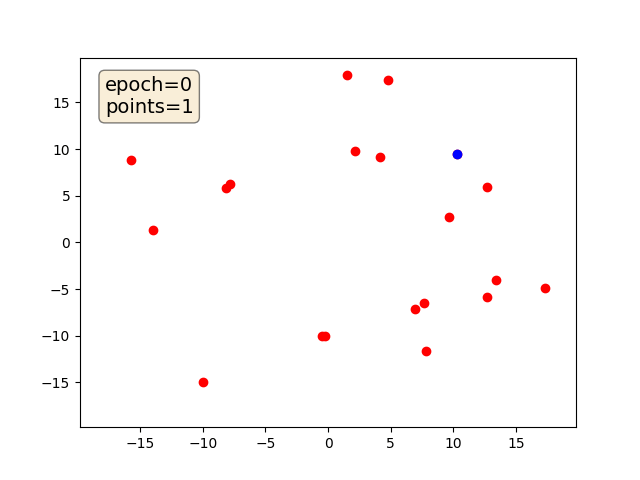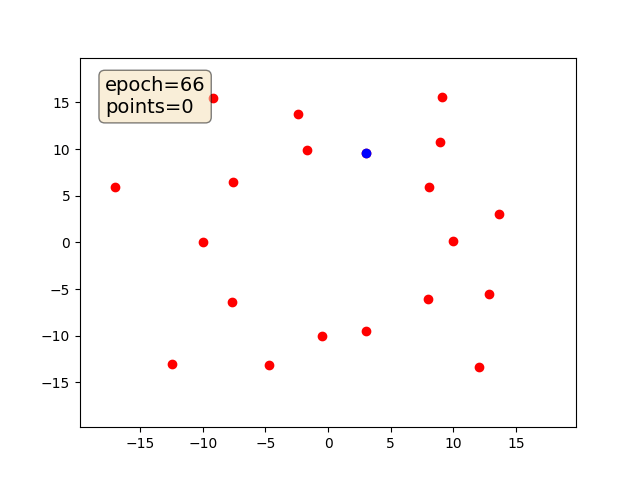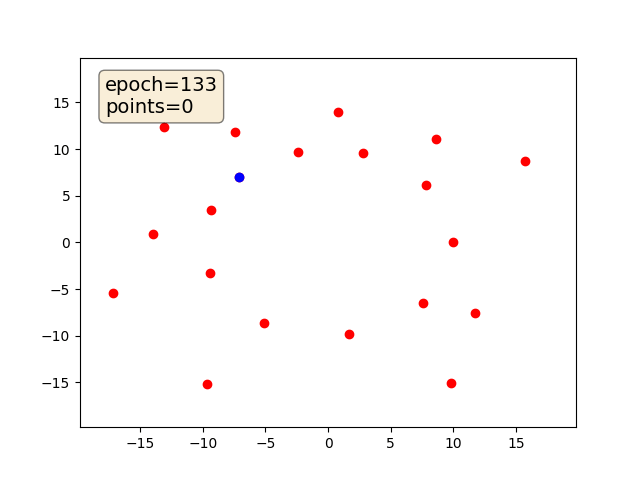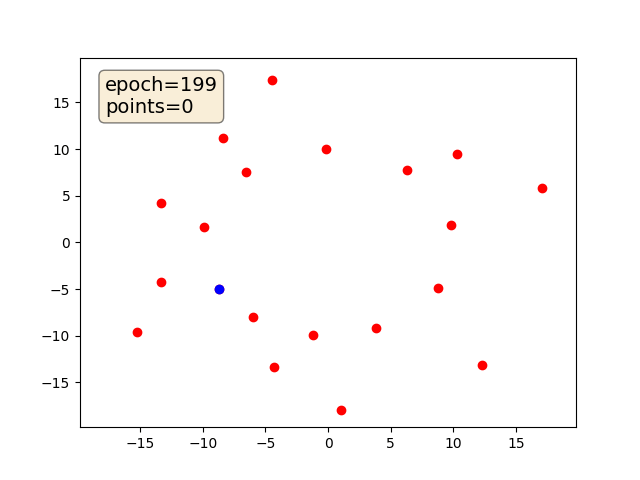
Среда в которой автомобили (окружности с радиусом 2 м) движутся по круговому треку с тремя полосами.
Обучить агента перестраиваться между полосами и двигаться с максимальной скоростью.
Должно получиться что-то такое (код DDPG – адаптиция того примера с хабра), только лучше:
| № варианта | Реализовать |
|---|---|
| 1 | DQN |
| 2 | |
| 3 | SARSA |
| 4 | A3C/A2C |
| 5 | TRPO |
| 6 | PPO |
| 7 | SAC |
Полезные источники
Не читала, но выглядит полезно: